Momentum Connect
An enterprise-scale platform to ingest data from a wide variety of sources and automate data engineering.

Momentum Connect Architecture
For any data-driven development, engineers and data scientists spend 80% of their time in data wrangling. Momentum Connect helps automate this process so as to improve the productivity of all stakeholders. You can speed up the data wrangling process by ingesting, cleaning, blending, and transforming a wide variety of data formats from external systems at high speed and scale.
Momentum Connect consists of the following four components
Ingester
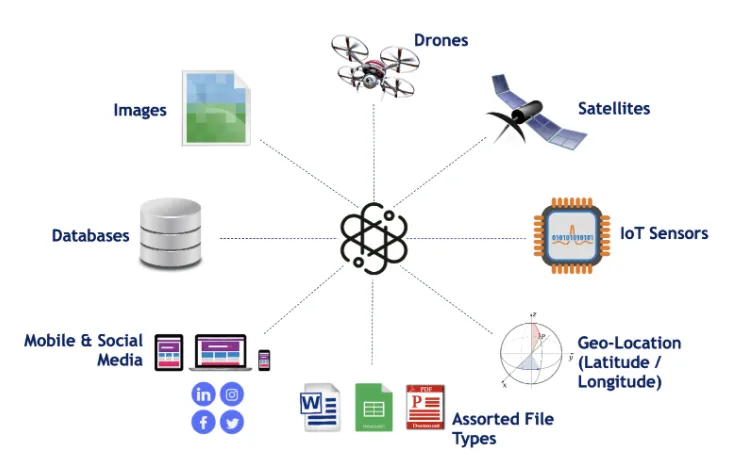
Ingester provides a set of connectors to pull data from a large number of systems. For example, you can connect and ingest data at a large scale from:
Ingester can ingest a wide variety of data formats:
Momentum provides a pluggable architecture to develop new connectors and attach to Ingester to be able to ingest data from systems that we do not currently support.
Transformer
Having accurate data is important. Therefore, data ingested from the source may require cleaning or correction. Moreover, you may require to blend data from different sources or transform them to be usable, meaningful, and trustworthy. Most machine learning algorithms require data to be in certain formats.
The Transformer provides a UI-driven approach to do data wrangling. Here is what you can do with the Transformer
Emitter
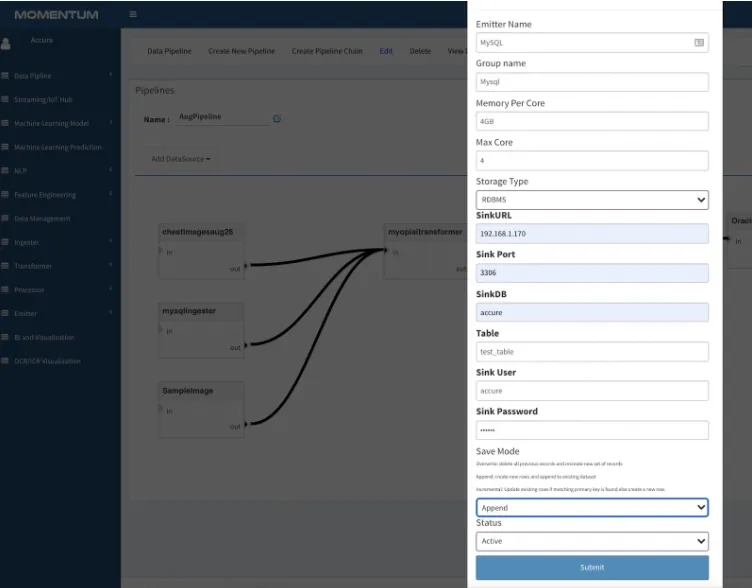
All data processed within Momentum are stored within a distributed file system. This allows us to create enterprise-scale data warehouses. However, it may be needed to transmit the data from Momentum to external systems. The emitter is designed to do exactly that.
Pipeline

Automate data ingestion and transformation using Pipeline. Here is what you can do with Pipeline:
Ready To Embrace The Future
If you are working on a data engineering or AI solution, trying to explore a use case, or building a proof-of-concept, please contact us for a one-on-one discussion.